
具体的に機械学習、ディープラーニングなどの説明の前に歴史的なことを含めておさらいです。
人工知能の定義

人工知能、人工知能と呼ばれていますが、人により定義が異なっています。もっといろいろな人の定義が知りたい方は「人工知能は人間を超えるか」をご参照ください。
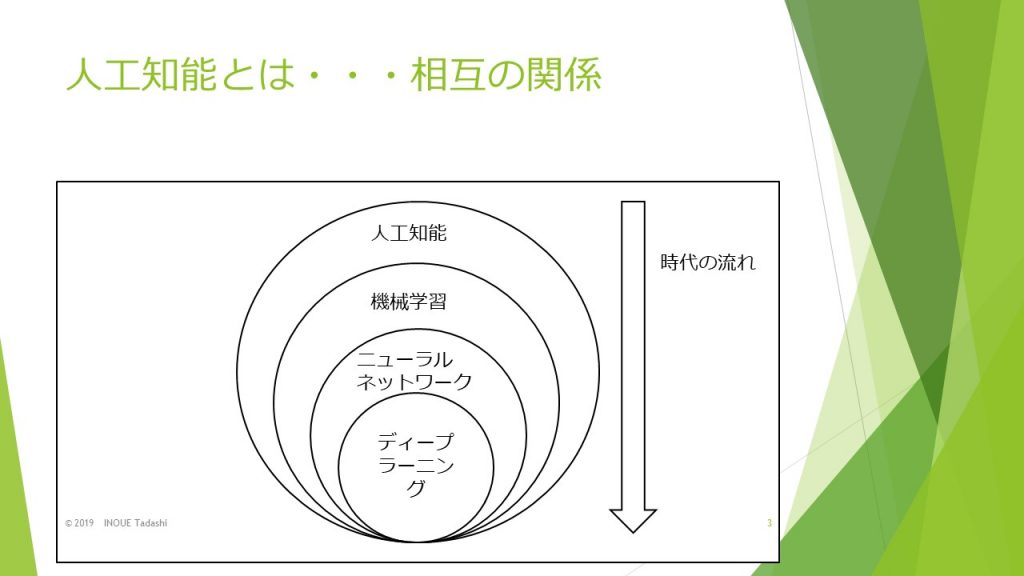
人工知能=機械学習、人工知能=ディープラーニングなどではなく、機械学習は人工知能の一態様であり、ニューラル・ネットワークは機械学習の一態様であり、ディープ・ラーニングはニューラル・ネットワークの一態様となっています。
また、1956年にアメリカで開催されたダートマス会議においてジョン・マッカーシーが 最初に人工知能という言葉を使ったといわれています。
さらに、人工知能、機械学習、ニューラル・ネットワークの順に考えられてきました。

人工知能と呼ばれているものにはレベル1からレベル4まであります。簡単な制御プログラムを人工知能と呼んでよいのかは疑問が残りますが、一応レベル1の人工知能とされています。

第1次人工知能ブームが1960年頃に起き、第2次人工知能ブームが1980年頃に起き、現在第3次人工知能ブームが起きているというように、いままでも人工知能ブームと呼ばれるものが何度かありました。
2029年には人工知能が人間よりも賢くなり、レイ・カーツワイルは、2045年には超越的な知性が誕生するというシンギュラリティが起きると主張しています。
ちなみに映画の「ターミネーター」においてスカイネットができた年が2029年です。

第1次人工知能ブームのときには、パズルや将棋などのゲームにおいて人間に勝利し、人間の知能を凌駕したので、人工知能への期待が高まりました。
しかしながら、実際の生活ではゲームほど単純ではなかったため、実際の生活に役に立たないことがわかりブームは終わってしましました。
第2次人工知能ブームのときには、法律、医療などの多くの知識を入力し、その回答を得るというエキスパート・システムが作られました。
エキスパート・システムは専門分野での有用性に期待されたのですが、知識を入力したり、その記述が大変であり、ブームが終わってしまいました。また、専門知識は増える一方なので、このころに知識を入力し始めたマシンに対して未だに入力されつづけているというものもあります。
現在はインターネットの発達により膨大なデータを取得することができ、ディープラーニングの考え方が現れ第3次人工知能ブームとなっています。

エキスパート・システム、ニューラル・ネットワークおよび遺伝的アルゴリズムをAI御三家と呼ぶこともあります。

第1次人工知能ブームは、推論・探索の時代と呼ばれていました。推論とは、「ある事実をもとにして、未知の事柄を推し量り論じること」であり、探索とは、「未知の事柄などをさぐり調べること」です。(デジタル大辞泉より引用)
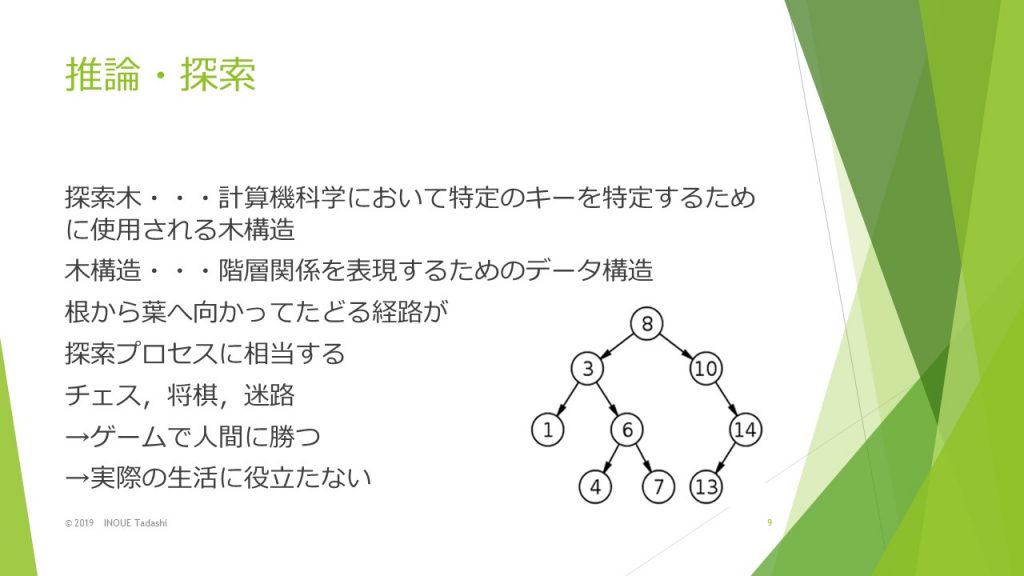
第1次人工知能ブームのときには木構造が利用されてゲームにおいて人間に勝利していました。但し、囲碁などのように異常なほどの組み合わせがあるものについては、単純にこのような木構造を利用するだけではゲームの世界であっても実用的ではありません。


エキスパート・システムでは、記憶されている知識についてはすぐに回答することができますが、必ずしも一義的に決まらないものについて回答するのは苦手です。
上記の文章は坂本先生の著書から一部引用させていただいたものですが、 トルコ語では対象の人物等の性別は区別されず、対象が男性であっても女性であっても、3人称単数は「o(彼、彼女、それ)」で、複数は「onlar(彼ら・彼女ら、それら)となるため、エキスパート・システムを用いて「彼女は外科医です。」という日本語をトルコ語に訳して、そのトルコ語を日本語にもどすと「彼は外科医です。」と訳されてしまいます。これは、「外科医」は男性であることを示す文章が多いことに起因しています。
同様に、「彼は看護師です。」という 日本語をトルコ語に訳して、そのトルコ語を日本語にもどすと「彼女は看護師です。」と訳されてしまいます。これは、「看護師」は女性であることを示す文章が多いことに起因しています。

機械翻訳は、ルールペース翻訳、統計翻訳機械、ニューラル機械翻訳というように発展してきましたが、現在のニューラル機械翻訳において話題となったのが地下鉄の「堺筋線」が “Sakai Muscle line”と英訳されてしまったことです。これは、「堺筋線」という一つの文字列よりも「堺」、「筋」、「線」という文字での学習量の方が多かったことに起因します。一般的には学習量が多いほど翻訳精度が向上するのですが、学習量が多かったために誤訳が生じた例です。
(弁理士 井上 正)


